
HISTORY PROJECT
I spent almost all of September exploring my personal past. I figured out several techniques for collecting files by date and constructing monthly summary videos from the years before I started creating worklogs and this written log.
This turned out to yield a lot of useful information.
My main methods were:
- Using GNU ‘find’ to search for files by date range.
- Using SVN commit logs.
- Searching by date for conversations in Gmail, in my ‘Sent’
folder (because those are the conversations I took part in). - Searching for posts by month on Patreon.
- Production Log and WordPress posts.
- Searching my complete data dump from Facebook that I got in 2019, as well as following the links back to the Facebook site and to offsite links.
This turns out to be pretty effective — maybe more so than the daily worklog screencasts. In fact, I want to start incorporating these into my current monthly summaries, and I plan to reduce the amount that I screencast daily (I’d like to confine it to actual production and development work, eliminating things like the worklog production that aren’t very informative — just noting the time used).
I still feel a little funny about spending so much time on this, but I actually learned a lot from it. I finally scripted the file collection process with Python, and gathered files all the way back to 2008, although I’ll likely have to run it again, because some things choked. The script is kind of brittle, but it doesn’t have to be that robust for this project.
Sep 12, 2020 at 4:01 PM
Collecting Project History (Part 1)

Early preview of the set for the “Central Universal Market” in Baikonur
This project has been going on for about 8 years now, so there’s a lot of history to dig through, and I have already got a lot of old files cluttering up my work space. I don’t really want to get rid of them, because I hope to make a “Making Of” history at some point, and I want that history for myself.
In fact, since January 2019, I’ve been logging almost everything I do with my daily “worklog” screencasts, which serve as motivation, accountability, information for future time management, and documentation of my previous work.
In that time, I’ve managed to save a lot of time and trouble on multiple occasions by being able to go back and check how I did something or at least when I was working on something in the past. It can be quite handy for remembering where I stored things or checking the command syntax or exact steps I used.
In addition to these daily logs, I also make monthly summaries, and as I was doing that for August, and catching up on the previous months of 2020, I started wondering if maybe there was some way to extend this history prior to 2019, by using other sources.
So I started brainstorming about ways to do that.
Earlier this year, I had experimented with using GNU “find” to simply collect files (especially graphics files) from a specific period in time, for this purpose. And this was a good start.
The Subversion repository for the project specifically tracks changes to the source file, so that was also a fairly obvious source for information, although commit logs tend to be kind of dry and minimal. They’re also not that easy to read straight out of Subversion, so it helps to format them better. And I found a pretty good way to do that.
But I also realized that I could get quite a bit of information from the various tools and platforms I use. By exploiting date-based searches on each of these platforms, I could bring up enough information to make pretty effective visual records of what I was doing during each month.
I learned a lot of interesting things from doing this, and I thought I would share the results here.
In this first part, I’m just going to talk about what I did on the Linux command line, to organize the available files I have already got on my hard drive. In the second part, I’ll talk about how I used online platforms to collect my history, and a possible third will address how I put these together into a coherent video a few minutes long for each month of the project.
Obviously, this is quite specific to my own needs, but you should find enough here to work out your own solution, should you want to do something similar.
The rest of this article is also attached in text format, to make it easier to copy and paste the bits of scripting and commands I included.
DATA-MINING PROJECT HISTORY: SOFTWARE NOTES
These aren’t scripts as-yet, but this is my collection for Linux shell tricks to collect data from my projects for the years prior to recording organized logs.
To do this, I relied heavily on outside platform resources, but also on my Linux filesystem and especially file modification dates (usually also the creation date).
I’ve used C-Shell csh and Turbo C-Shell since the late 1980s, so I tend to remember how to do things in them. Even though they are not the favorite shell for scripting, it’s what I can remember for looping, so I’ve used tcsh here in these examples. Of course, you can do this in bash as well.
In reality, I’ll probably rewrite this in Python or Bash in the future, if I do decide to write it into a script. I might also just continue using these command ad hoc.
I got a LOT of hints on this from various web searches online, though I’ve made changes to suit my situation.
TOOLS FOR DATA-MINING
Make directories to collect “clips” for the year:
$ cd /path/to/history $ tcsh > mkdir 2017 > mkir 2017/clips > foreach n ( 01 02 03 04 06 07 08 09 10 11 12 ) foraach? mkdir 2017/clips/$n foreach? end >
From here on, I’ll only demonstrate commands for January 2017. Obviously, I did all 12 months (these are formatted for reading clarity here. In the attached file, I presented them without line-wrapping, to make them easier to paste).
1) COLLECT
First of all, I collected videos, images, drawings, text, and PDF documents into directories for the year (cd into each of the main directories where you keep project files. Or, if you’re really brave, you can try this from /, but it’ll probably get a lot of irrelevant stuff):
$ cd /old_and_current_working/path
You’ll need to loop through the date ranges you want. I did this for each month, and I had to loop manually to get it right. Find will complain if you try to use non-existent dates like ‘2017-02-31’. I suppose I could’ve used a full time stamp for the first second of 2/1 instead, but I just used ISO dates because it’s easier for me to remember the format:
$ find . -newermt '2016-12-31' -not -newermt '2017-02-01' \
\( -name '*.jpg' -o -name '*.gif' -o -name '*.svg' \
-o -name '*.pdf' -o -name '*.txt' \
-o -name '*.avi' -o -name '*.mp4' -o -name '*.mkv' -o -name '*.webm' \
-o -name '*.webp' -o -name '*.blend' -o -name '*.png' \) \
-not -path "*/mediawiki/*" -exec cp -a {} /path/to/history/2017/clips/01/ \;
Note that I have used ‘-not -path’ to exclude mediawiki files. This is because I have backups of a MediaWiki site, and MediaWiki stores some files under directories which use image extensions. I could alternatively have used ‘-type f’ to only search for ordinary files.
You might also want to find a good path match for cache directories where thumbnails get stored, or you will get lots of those in your search (I had quite a few of these when I did this from my home directory).
SVN Commit Logs
I also pulled the SVN commit logs from my repo, selecting the revisions by date-range.
$ cd /path/to/svn/working/copy
$ svn log -r {2017-01-01}:{2017-02-01} --xml > .../svn_commits--2017-01.xml
This pulls the range of revisions from the last one prior to the first date to the last one prior to the second date. This will typically start with one revision from a prior month, but I find that’s useful.
This one can be looped through the months pretty easily, exploiting the ability to do math using tcsh:
$ tcsh
> foreach m ( 01 02 03 04 05 06 07 08 09 10 11 )
foreach? @n = m + 1
foreach? svn log -r "{2017-$m-1}:{2017-$n-1}" --xml \
> /masters/terry/Worklog/History/2017/clips/`printf "%2.2d" $m`/svn_commits-2017-$m.xml
>
Of course, you could do an outer loop for multiple years, but I leave that to you.
2) CONVERT
Clear out files below 200×200 pixels, assuming these are thumbnail images:
$ cd /path/to/history/2017/clips/01/
$ mkdir th
$ identify -format '%w %h %i\n' *.png *.jpg *.gif | \
awk '$1<200 && $2<200 {print $3}' | xargs -I {} mv {} th/
$
This uses “identify” from the ImageMagick suite to find and print the filenames along with dimensions. That’s then piped into “awk” (first time I’ve ever used it!) to match width and height both less than 200 pixels, and then that output is fed to “xargs” which then executes “mv” to move those files into the ‘th’ directory (you could also just “rm” them, but I wanted to avoid destroying them until I was sure it worked right).
I also made a collection of “small” images, which I will collect into groups for display:
$ cd /path/to/history/2017/clips/01/
$ mkdir Small
$ identify -format '%w %h %i\n' *.png *.jpg *.gif | awk '$1<400 || $2<400 {print $3}' | xargs -I {} mv {} th/
This now checks to see if either width or height is below 400 pixels, and moves them into a directory. You could also use a different expression to catch very tall or wide images (images with extreme aspect ratios) for special handling, but I just handled those cases on a one-by-one basis.
PDF Documents
For use in a video, I want my PDF files broken into collections of pages, converted to PNG format. This can be done like this:
$ tcsh > foreach pdf ( *.pdf ) foreach? mkdir $pdf:r foreach? pdftoppm -png $pdf $pdf:r/$pdf:r foreach? end > mkdir pdf > mv *.pdf pdf/
This makes directories based on the filestems and copies PNG-converted pages into them.
These can be loaded as “Slideshow Clips” in Kdenlive.
SVG Drawings
Scalable Vector Graphic files are theoretically very portable, but in practice, rendering can be inconsistent. Most of mine were created in Inkscape and so the safest tool to render them accurately is Inkscape, which CAN be scripted:
> mkdir svg_pngs > foreach svg ( *.svg ) foreach? inkscape --without-gui --file=$svg --export-area-drawing \ --export-png=svg_pngs/$svg:r-drawing.png foreach? inkscape --without-gui --file=$svg --export-area-page \ --export-png=svg_pngs/$svg:r-page.png foreach? end > mkdir svg > mv *.svg svg/
This renders them in two different ways — one to get the whole drawing, and one to match the page in the document. This helps, because sometime when I’m not drawing for printing, I draw outside the page. Other times, the drawing is very small on the page and there’d be a lot of wasted space. This way, I can choose the one that’s a best fit, or in some cases, use both.
Also, I tuck the SVG source away in a sub-directory to reduce clutter.
Text files (TXT)
I can paste text into my titler in Kdenlive, but it tends to freak out if the lines are too long. So it’s best to prepare the files with automatic line-wrapping. There are various ways to do this, and the results will depend on how you tend to write your notes. But my notes work pretty well with these options on GNU “fmt”:
$ tcsh > mkdir txt txt/orig > foreach txt ( *.txt ) foreach? fmt -cs -g 70 -w 80 $txt > $txt:r-fmt.txt foreach? end > mv *-fmt.txt txt/ > mv *.txt txt/orig/ >
This will line-wrap all the files, using “crown spacing” to check the indentation of paragraphs (this usually makes bullet lists look good).
I also use the “-s” option to avoid combining code samples (it tells fmt to only split lines, not try to combine them).
This shell loop moves the original files to txt/orig and the formatted ones into txt, for easy finding from the file browser in Kdenlive.
Make SVN Commit Logs Readable
The XML output from SVN is almost ready, but we need to add a line to tell it to look for a stylesheet for display in a browser:
$ sed -i '1 a <?xml-stylesheet type="text/xsl" href="svn_commits.xsl"?>' \ svn_commits-2017-01.xml
I also needed to copy the stylesheet into the directory. I copied them because Firefox is very fussy about where to find the stylesheet and won’t allow symbolic links or other tricks:
$ cp ../../svn_commits.xsl .
The XSL file is based on one I found online (Sorry, I didn’t keep the reference), but it’s very simple, and I’ve modified it. It basically just formats the output into a table.
Firefox will likely not show you the formatting XML, though, until you tell to accept the stylesheet from your filesystem. To do this, you’ll need to direct your browser to “about:config”, search for “uniq” and then flip this setting to False:
privacy.file_unique_origin
This is apparently a security issue, so I recommend you change it back after completing this process.
Once that setting is taken care of, you should see your XML file formatted in the browser. To create video for my worklog, I simply screencast as I scroll through the file (if it needs scrolling, or justrecord a few seconds of it open in the browser if not).
These are the basic command line steps I use to get my materials ready. The rest is done using the GUI environment, so I’ll document that in my next article.
Sep 14, 2020 at 4:00 PM
Collecting Project History (Part 2)
…or “How I Learned to Stop Worrying and Love my Facebook Addiction”
For the last week, I’ve been making an attempt to document the past of this project and my related work. In my last post, I addressed the methods I could use to get chronological access to files on my filesystem to try to find work I had been doing during each month of past years (before I started making a formal worklog).
In this second part, though, I’m going to address getting information from the third-party platforms I’ve been using.
Although I prefer to use mostly my own independent resources for this project, based on open-source software, the practical fact is that I’ve also relied heavily on third-party corporate “data silos” to publish a lot of project information and to communicate with other people about the project.
This has an upside, in that most of those platforms provide some kind of access to the information I have posted, which I can select chronologically. From this, I was able to recover quite a bit of information, which is largely what has allowed me to make a coherent account out of what I’ve found.
For each of these sources, I simply opened them in my web browser (Firefox), selected the appropriate range, and made a screencast while I manually scrolled through the information — a very low-budget and easy way to collect the information on video.
Here are the sources I used:
Production Log (WordPress)
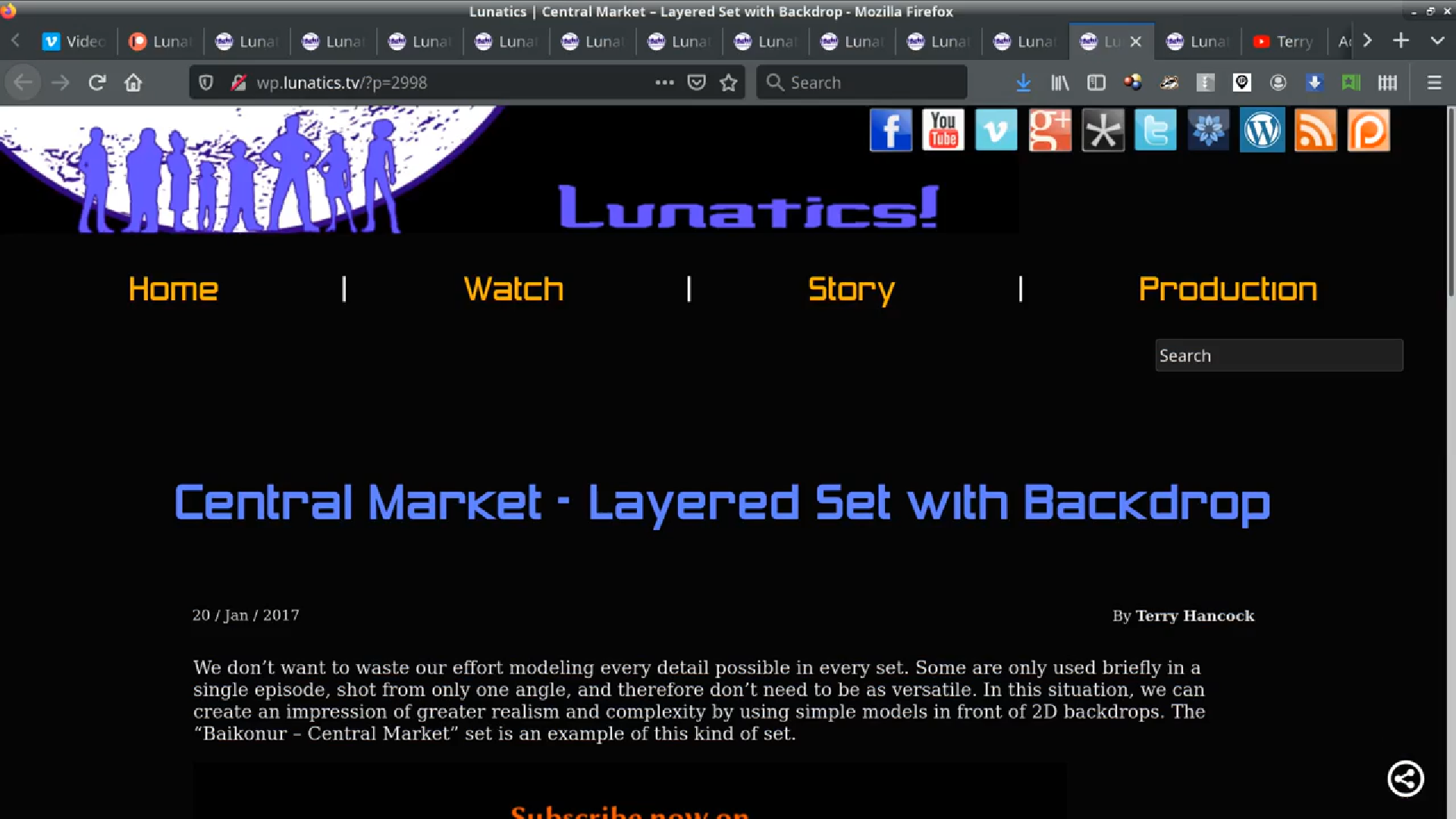
I wish this was kept up better, to be honest. But I have posted several very informative articles on the WordPress instance on the “Lunatics!” project site, going back to the beginning of the project.
WordPress is a “blog” with separate webpages for articles with dates. I simply needed to open the necessary dates in tabs, and then scroll through each one.
Patreon
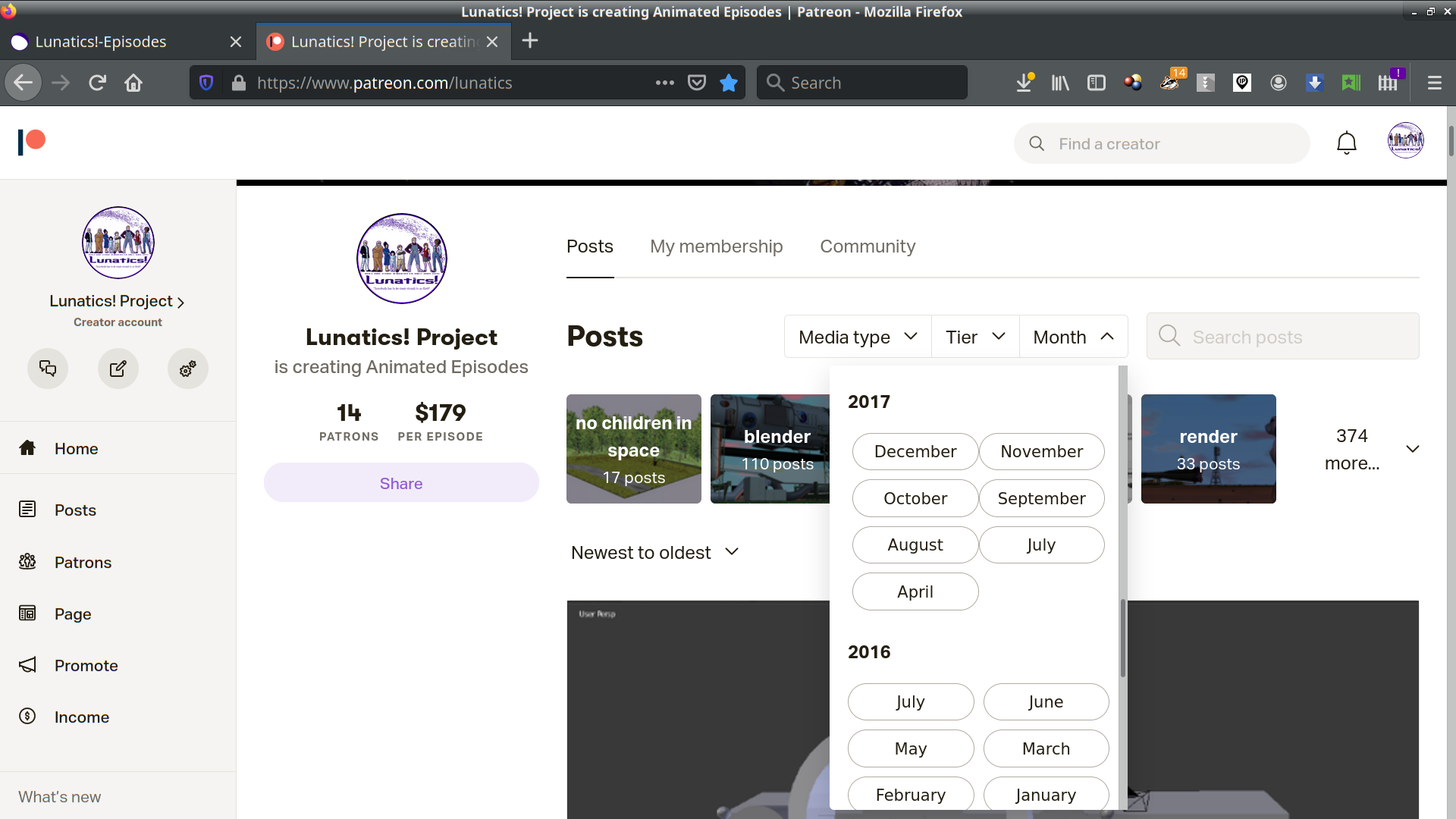
I’ve been posting pretty regularly on Patreon since the middle of 2017. Before that, they were much spottier, but I have posts going back to 2015.
Patreon makes this about as easy as it could be: they actually have a drop down to select project posts by year and month.
Vimeo

I publish behind-the-scenes videos on Vimeo every once in awhile, and in 2015 and 2016, I was pretty regular about it, with the “Two Minute Tutorials”. I’ve been a lot slower lately, but then I’ve been prioritizing working on the actual episode, so I don’t feel too badly about that (although I am still working on the “Film Making for Lunatics” series, which will consist of longer “case study” tutorials.
The creator view on Vimeo includes a data-based list of uploaded videos, and it’s easy to scroll through, find the dates, and download all from that table (of course, in many cases, I already have a copy of the video somewhere, but this makes it easy to find by the date I published it).
You Tube

Prior to 2014, most of my videos were on You Tube, rather than Vimeo. I haven’t gone back that far yet, but eventually I will start searching these.
Gmail

Most of my project communications have been on my Google mail account. I sometimes gripe about being so dependent on Google, but I keep using it, and I certainly did for all of 2010 to 2018.
There’s a lot there to go through, of course, but I found the simplest thing was simply to look for the email that I responded to — by searching my “Sent” folder. This was quite effective at locating the interesting conversations worth documenting.
The only real downside to using email like this is that I may not be able to publish a record based on this, because some of the messages may be confidential, and redacting them for publication is too much work. But it definitely works for my private use.
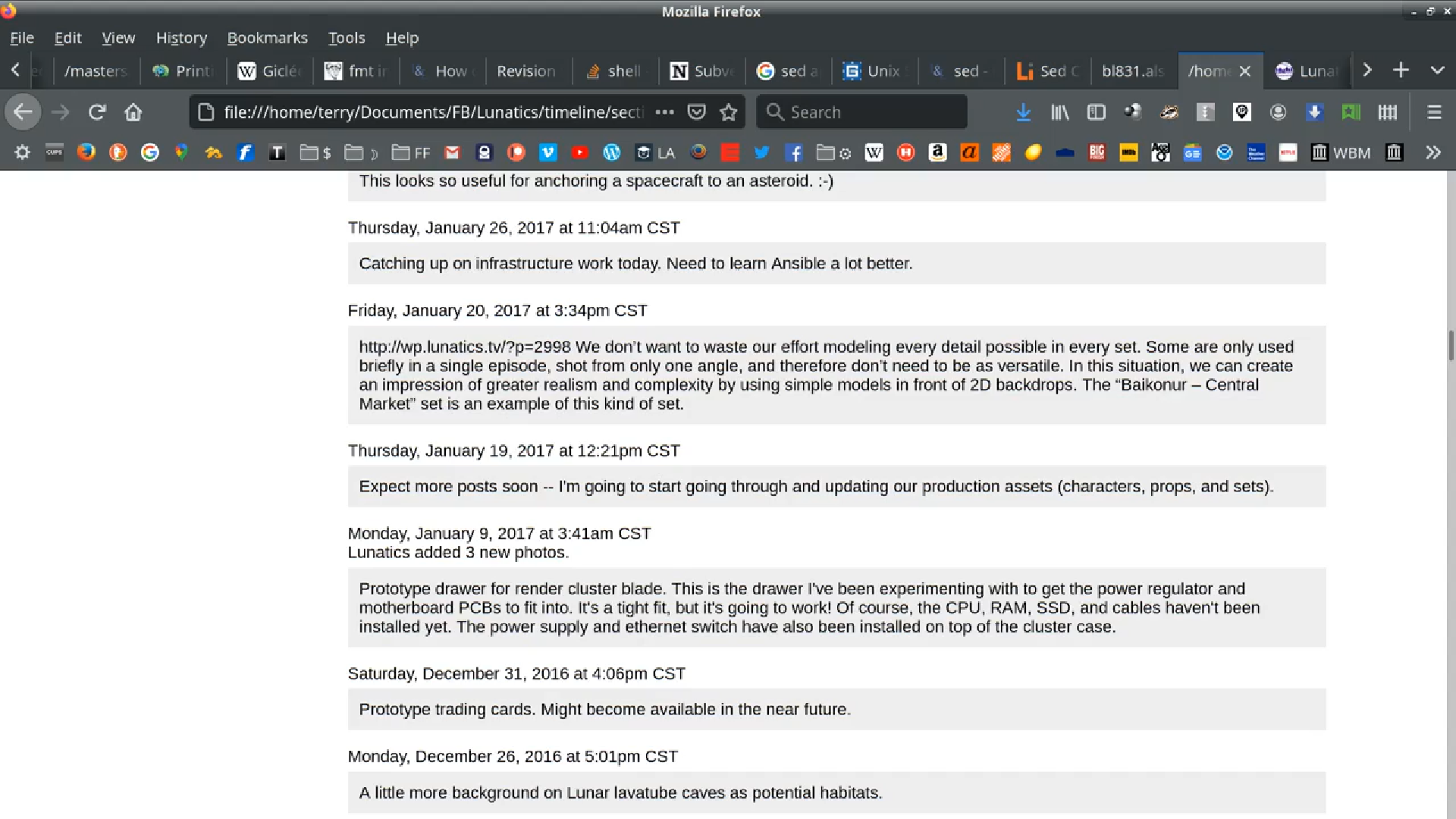
I maintained the “Lunatics!” page on Facebook as the primary social-media outlet up to about the middle of 2017, when I switched over to putting short posts here on Patreon first.
I sometimes feel bad about how much time I spend on there, but the upside to that is that I posted on my personal Facebook for pretty much the entire run of this project, and I often talk about what I’m doing on my personal FB page:
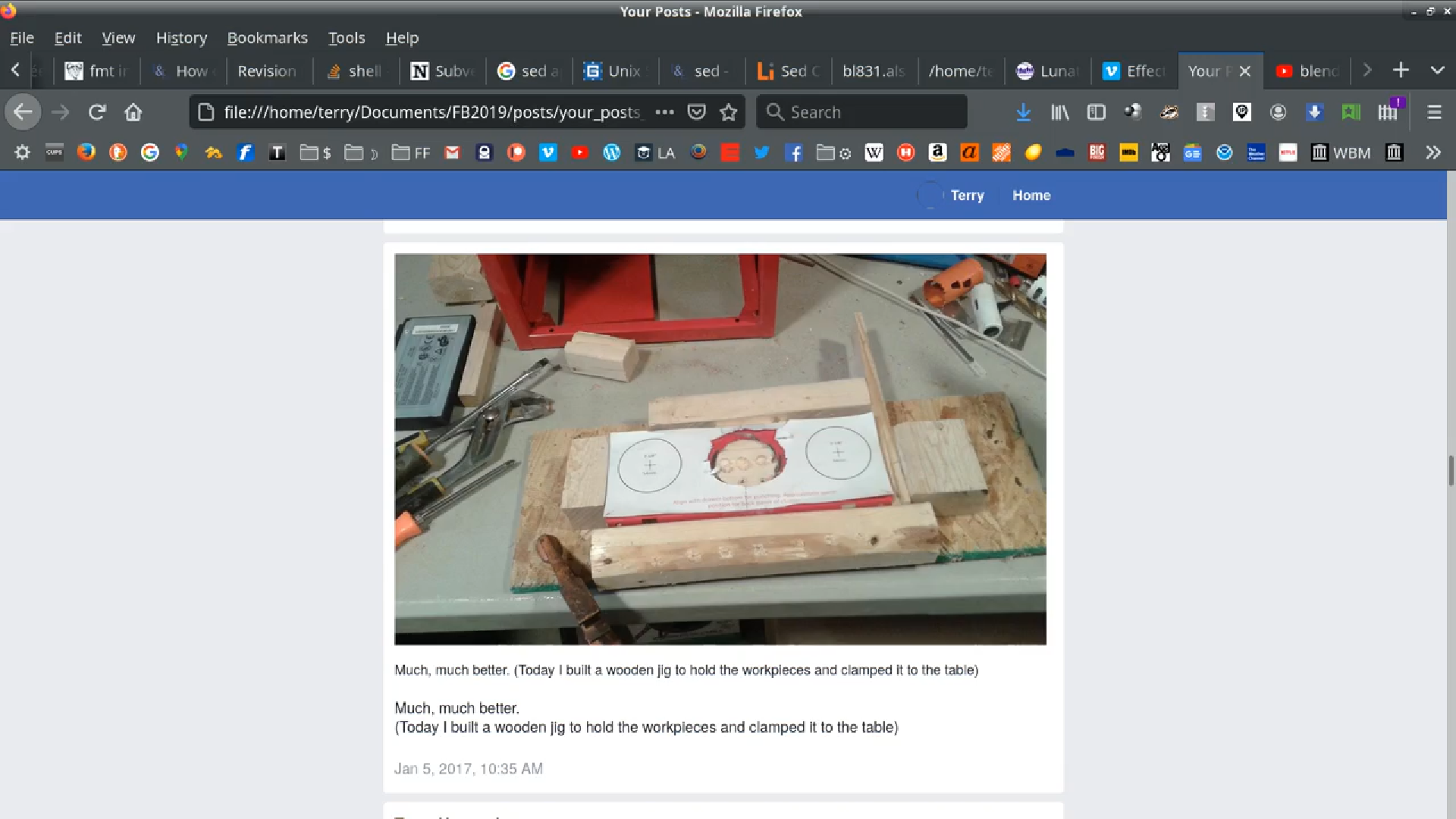
Both the “Lunatics!” page feed and my personal “Timeline” are pretty detailed records of what I was doing — perhaps better than any other source, although there’s other clutter on my personal Facebook page in particular. But one thing about generating a screencast by scrolling manually in the browser, is that I can whiz through the dull stuff and hover on the more interesting posts.
So I feel a little weird about it, but it’s a great record for the time in which I wasn’t keeping a reliable project log (which was a lot of time).
For this, I used the data dumps I collected from Facebook in 2019, which include my personal and page data). So this data was already sitting on my filesystem.
Google+ (Takeout)
Similarly, in 2016 and before, I have date from Google’s social media experiment, “Google+”, which are in the “Google Takeout” data dump I got from them some time back. I haven’t gone back to 2016 yet, but I believe this will be useful when I get there.
Kickstarter
Once I get back to about 2014, I should be able to look up Kickstarter updates I posted. And if I get back as far as 2010, the very earliest “Lunatics!” related posts were articles I wrote for my blog at Free Software Magazine, for which I have date-based archives, already.
While these are no substitute for the documentation function of my daily worklogs, they do compare pretty favorably with my “monthly summaries”. And in fact, I found that some of them provided more specific and better-organized data than is easy to glean from the huge amount of screencast data from my worklogs (which I play back at 1800X speed in my monthly worklogs, so it’s really only possible to get the gist of what I was working on, without any real detail. If I sent or received email during that time, it might be easy to blink and miss it. Having a list of subject headings is clearly better. So is a simple list of SVN commits.