Migrating data from one system to a radically different system typically requires a lot of thought and reorganization, and this post is about the plan I’m formulating, which I hope will be workable. We still won’t want to save everything, but on the other hand, with TACTIC, we will be able to practically manage a lot more assets. Storage limitations also greatly constrain how much we can make publicly accessible, but that too is a problem I already have plans to solve.
A New Way of Looking at Assets
First of all, I’m going to draw a very different picture of ALL of our project assets than I have used before. This version attempts to classify assets more in the sense of how they are used and how they should be published:
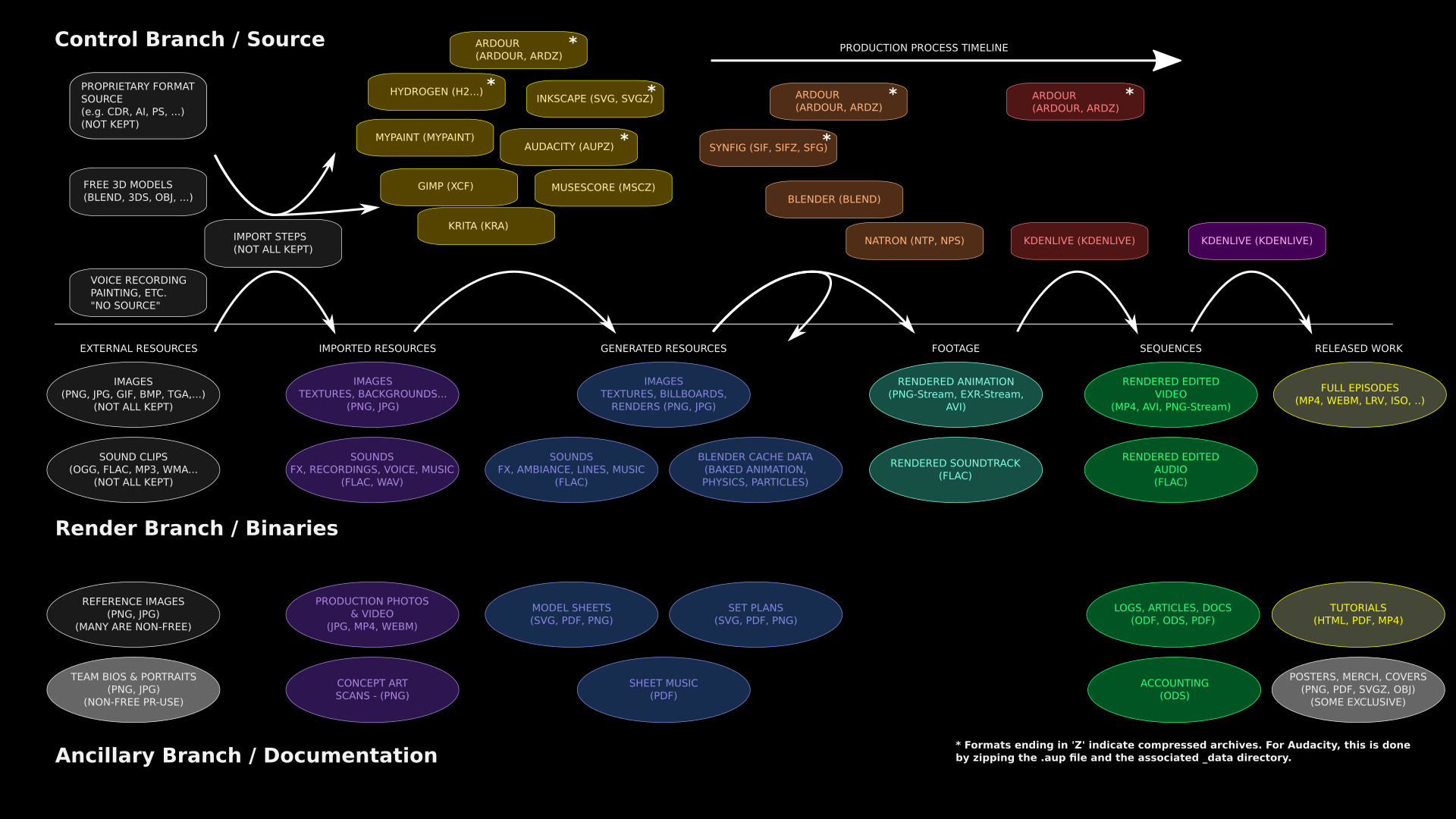
Code-like and Data-like Assets
I’ve divided the assets into “code-like” and “data-like” categories. The dividing line is somewhat arbitrary as the definitions are fuzzy in practice. The general idea, however, is that “code-like” assets are basically control files telling how to procedurally construct something from prior assets, while “data-like” assets are generally more self-contained and make sense to publish on their own. In contrast, “code-like” assets are much more likely to have dependencies on other files, through reference links. “Data-like” assets are generally in simpler, common formats that can be opened by many applications, whereas “code-like” assets generally target specific software, and while they can be opened by other software, they usually do not produce consistent results.
“Data-like” assets can be further divided into “rendered” project elements, and “ancillaries”, which are stand-alone data-like assets which exist as plans or documentation for the project. This gives us three “branches” which may need to be treated in qualitatively different ways. I’ve laid these out vertically in the chart above.
Production Process Order
Horizontally, I’ve organized the chart according to production sequence, with “input” assets on the left side being transformed by successive steps into “output” assets on the right. Conceptually, the “code-like” and “data-like” assets tend to be interleaved on this timeline, since the code-like assets are generally used to apply the processing steps to the data-like assets, converting them. So data-like assets to the left of a code-like asset are typically depended on, while the assets to the right are generated by the code-like asset as output.
So this structure essentially follows our production “pipeline”, identifying particular steps along the way which may be worth saving in our asset-management system.
The leftmost column in the diagram shows “external resources” that we haven’t contributed to — we’ve merely collected them. This includes both “passive collaboration”, such as music tracks from Jamendo or images from Flickr (or Google image searches), and “active collaboration” which requires importing from proprietary or non-standard formats, such as Adobe Illustrator or Garage Band.
This zoo of input formats typically requires some kind of manual import work to get into a usable format. We may also apply stylistic rules, such as converting photorealistic Cycles-based Blender models to NPR models and the Blender Internal renderer. This gives us our “imported resources” in the second column. These are derivative works, with shared authorship between the original author and project members.
To the right of these are “generated resources”. They represent original project work, such as decal textures created in Inkscape, backgrounds painted in Krita, and ambient sound environments created in Audacity, based on the supporting imported assets, or in some cases, produced entirely from scratch. There are also ancillary assets in this category, such as plans drawn in Inkscape to support creation of models.
These are then used with 3D models, sound design files, and so on to create rendered “footage”, and that then provides the raw material for video or audio editing to produce video and audio “sequences”, which are finally (at long last!) combined into finished and packaged “released work” — mainly the series episodes, which are the whole point of this project.
Current Publication Status
What we are doing now with these assets is outlined in this second figure:
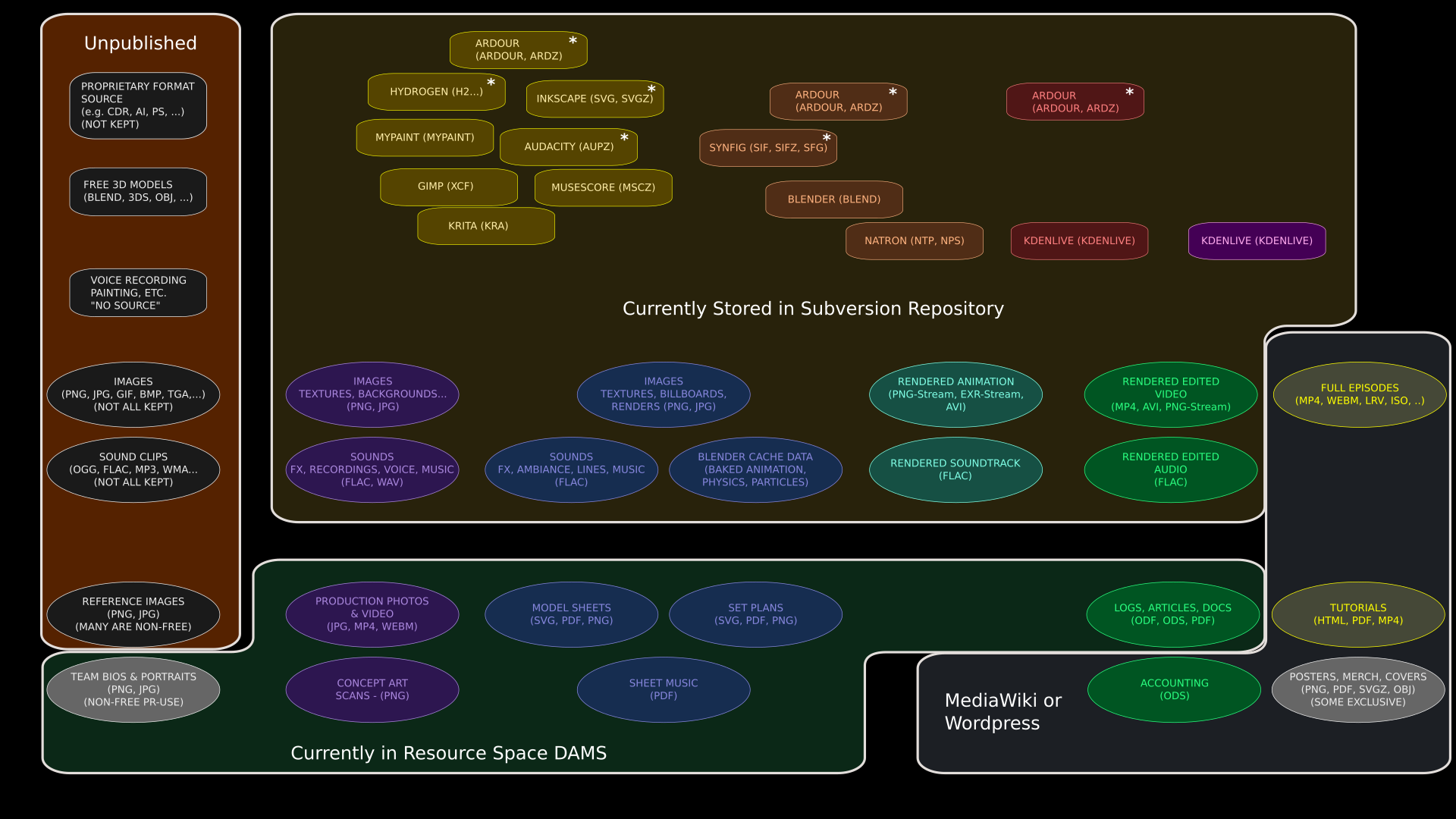
Few of the collected non-original assets have been uploaded.
We don’t own these assets, so we don’t control how they are licensed, though we must be careful about how their licenses affect the licenses we apply to our own work (that is, we must respect copyright and copyleft requirements on them). Copyright sometimes means we have no right to publish these assets at all (as with images found via Google), but Fair Use means we are free to consult them — as is the case with reference images used to create 3D models of real places, for example. Sometimes, as with NASA photos or databases, we are nevertheless free to publish them, because they are “Copyright Free”, “Public Domain”, or simply available under (various) “Creative Commons” licenses. Above the line, we have also have some “code-like” assets, such as 3D models from BlendSwap or other sites which permit public-domain or CC-licensed models to be published online.
These are sitting on my harddrive at home, which is okay for me personally, but doesn’t allow other members of the project to access them, let alone the public.
A smattering of ancillary assets have been uploaded in our Resource Space DAMS on the website (this is currently very incomplete). Most of the control files, 3D models, audio project files, as well as imported image data are stored in our Subversion repository as the “source code” for the project, along with some rendered animation used to make our preview trailer and other elements we’ve already completed. And finally, we have a few assets that are published on our website only, via MediaWiki or WordPress (such as the “Earth” audiodrama or the breakdown of music tracks for “No Children in Space”).
Conventions, Limitations, and Goals
Now, to understand better where we need to go with this, it will help to try to match up these classifications of assets to the usual conventions of open source software projects, and what that implies we are obligated to do as an “open source” project and also, of course, what we can and can’t do legally under copyright and copyleft restrictions as well as a few restrictions based on “publicity” and “privacy” concerns — open as we are, there are some limits. Our desire to operate as a self-sustaining project also means we’ll reserve a few things to be exclusive for backers and contributors.
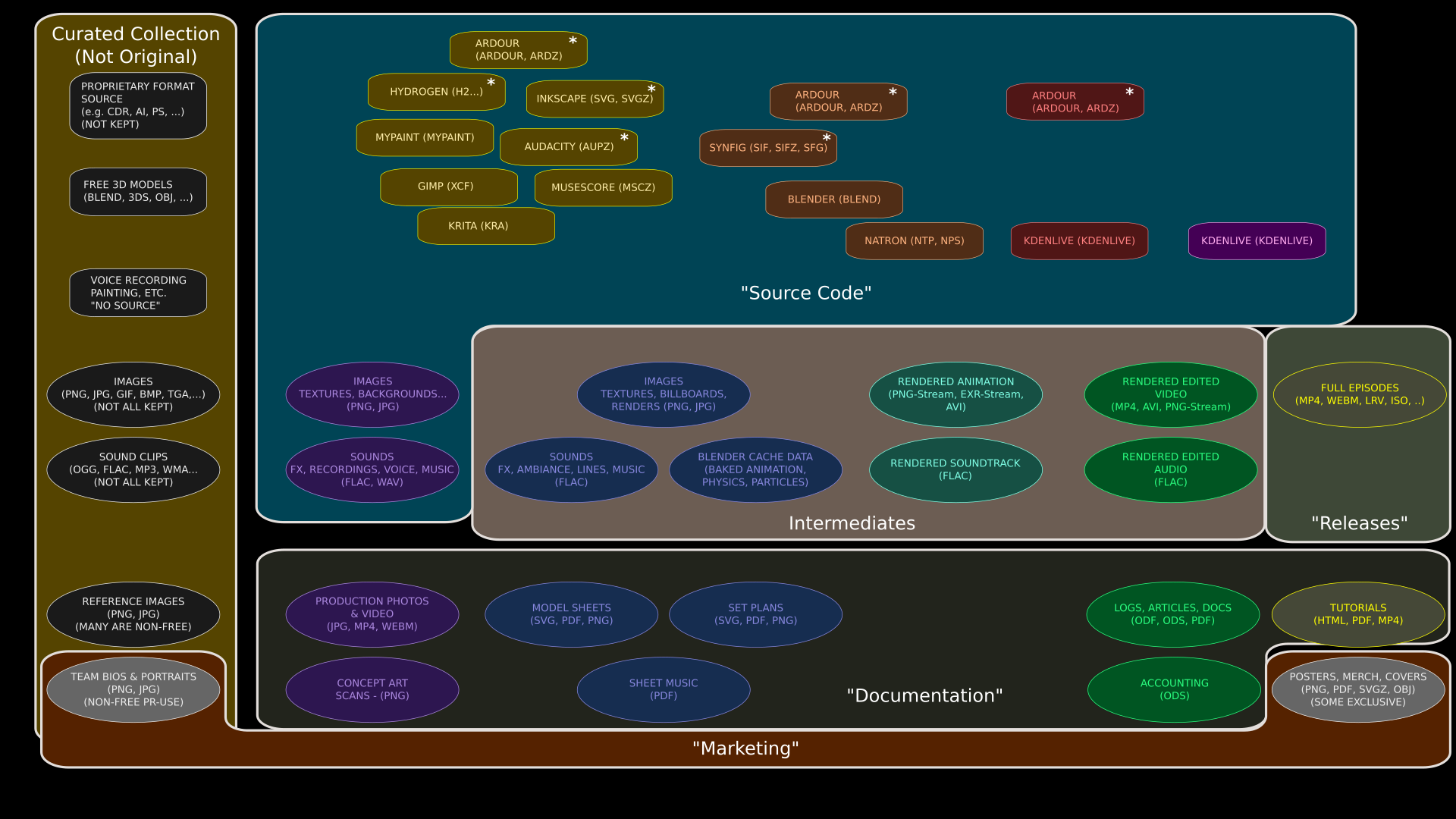
To be considered “free culture” really only requires that our final output — the “Releases” are under a free license (Creative Commons Attribution-ShareAlike 4.0 in our case), so that’s a relatively weak requirement.
The stronger requirement is to be “open source” or “open film”. This has always been a bit more vague, since the concept of “source” derives from software development, where the definition is much less fuzzy. Just how many of our assets are analogous to “source code” and therefore obligated to be published along with our free-culture releases?
If we follow the usual conventions of software development and think of our authoring tools as “compilers”, our “code-like” assets as “source files”, and the data they apply to as “resources”, we get the domain in blue shown above. This is a bit less than what we currently keep in Subversion — it omits the intermediate assets that we create from these elements. By the usually conventions in open source projects, these “Intermediates” wouldn’t be kept at all — they’d be eliminated to save disk space, because the user can regenerate them.
However, that skips over an important issue with multimedia files — the regeneration step can be painfully long even for us, and much more so to a typical user who doesn’t have their own render farm on hand. It’s highly desirable to keep at least those intermediate assets which are very time and CPU intensive to recreate. By and large, though, those will be the same resources that require enormous amounts of disk space to store and bandwidth to deliver. As a result, the decision to provide CPU-intensive intermediates pretty much means we might as well include most if not all of the intermediates that we generate (we might not want to keep every version, though!).
Most of what the first diagram called “ancillary” files would probably be regarded as “Documentation” by the conventions applied to open source software projects, and these are considered to fall outside of the project for licensing purposes. It’s not uncommon, for example, to find open source projects that are sustained financially by selling proprietary documentation. So we’re pretty much free to do what we want with these elements, although it’s good PR to make a lot of free ancillaries available.
A few items are used expressly for public relations and fundraising purposes,which it doesn’t make sense to publish, although their components can be found in the other categories. And although cast and crew photos will probably be in the DAMS, they will have the usual usage restrictions, due to privacy and publicity considerations.
That leaves only the “external resources”. There’s a number of good reasons to publish these on our site, even though many are already available somewhere on the web. These are essentially a “curated collection” of generally free-licensed work, which may be useful to visitors. This will also makes it much easier for our own team to collaborate using these assets, and allow them to be tagged for easier searching.
Next Steps
Where this leads us is to some useful ways to organize files for importing into TACTIC, and systems for tagging them, based on the classifications outlined here, in addition to the existing source hierarchy (which is based on what part of the production the files contribute to, such as “sets”, “characters”, or “props”). One of the advantages to tagging for asset management, is that it doesn’t have to follow a single hierarchy, so you can change the way you look at the same data, as I’ve done in this post.
I’m currently trying to find all of the existing project assets and get them organized for migration into TACTIC (I’m also still working on the deployment scripts for the website, including TACTIC — more on that soon).
